A conference paper on semantic communications has been accepted by IEEE/CIC ICCC 2023, and will be presented orally by me during the conference (10-13 Aug., Dalian). Preprint version will soon be available on arXiv.
背景概述 | Brief Intro
随着各种可复用的资源被逐渐深入研究,通信的研究方向逐渐转向了新技术赋能,例如这些年来研究十分火热的可重构智能表面1 (Reconfigurable Intelligent Surface, RIS),通信感知一体化2 (Integrated Sensing and Communication, ISAC),以及人工智能技术3等。语义通信技术虽然是一项相当有年龄的技术4,但在近年来自然语言处理的深度学习方法的催化下再次进入了研究者的视野。在上古的研究中,研究者就已经将通信系统按照功能分成了三个阶段,圣经原文如下:
- Level A (Technical): How accurately can the symbols of communication be transmitted?
- Level B (Semantic): How precisely do the transmitted symbols convey the desired meaning?
- Level C (Effectiveness): How effectively does the received meaning affect conduct in the desired way?
那么显然我们几十年来的通信系统仍然处于阶段A,即大家都在实现通信符号的精确传输,也因此开发了整套编解码、调制解调、同步、信道探测、波束管理等方案。然而实际上通信系统真的需要维持每个比特的正确性吗?我们有很多方式可以证明并不需要,例如下列句子中,若传输中由于带宽/干扰等原因产生了若干字母的判决错误,人类对自然语言的理解可以有效地发现并纠正错误
1
2
> I have heard the mermaids singing
> I h?vt hea?d tse m?rmaid? s?nging
除此之外,在我们的生活中也不难发现,一张图片包含的信息(或者一次会话中可能利用到的图片中的信息)往往只是整张图片的很小一部分,相比之下视频中携带的信息密度就更低了。
题外话,目前的h264等完全成熟的编码方案都已经充分考虑了时间上的依赖性,I、P、B帧结构早已成为了视频编码的基本标准之一,其中除了关键帧I帧之外的其他帧(P,B帧)大小只是I帧的$1/30$左右。
在海量的数据驱动下,图像的结构相似度、峰值信噪比等成为了衡量图像相似度的重要指标,目前的许多论文也采用类似方案评估语义通信方案的性能;对于视频,Netflix则提出了VMAF混合评估模型,用来衡量视频在人类感知模型中的感知损失系数5 (Perceptual Loss)。但实际上上述方案都是一些对主观质量评估的近似模型,对于描述传输结构中所蕴含的语义信息量的指导意义并不高。
由于香农的信息论是基于二进制比特的,因此也并不具备描述语义现象的能力。直观上讲,我们或许只需要提出一种合理的语义相似度方案,并根据语义相似度目标进行优化即可,然而这实际上是非常困难的————毕竟就连人类自己也无法精确地描述出自己对语义相似度的评判准则,更无法对两句candidate文本的相似度给出float32级别的定义。
于是万事开头难,我们希望首先通过实验验证语义通信方案,再逐渐通过深入的实验数据发展理论。本文中我们将尝试首先验证语义通信是否能节约传输开销,首先明确该方案是否有进一步研究的价值,而后续研究中我们将逐渐探索语义通信技术的极限。本文的主要实验如下
- 借助Transformer模型,我们提出了一种文本语义联合编码的基本架构,将每一个词片编码为固定长度的二进制比特并基于该embedding重建语义。
- 借助公开数据集,我们设计了一个新的混合复述数据集 (Rephrase Dataset),并通过该数据集训练了上述语义通信模型。
- 我们对语义相似度评估做了第一步尝试。
系统模型 | System Model
编解码器的基本结构如下所示,编码器部分我们采用了预训练的BERT模型,这是由于我们尝试train-from-scratch时发现所构造的数据集不够general,难以构建一个相对完整的语义数据库。该预训练模型将随着Decoder的训练同时fine-tune;解码器部分采用简单的Transformer-Decoder模型,这里我们对Transformer结构的修改很少,不同点主要体现在传输部分。在完成编码之后,我们可以选择将信号进行拼接与比特交织之后送入二进制信道。该过程梯度可以选择straight-through的方式实现,而在传输后我们迭代译码。
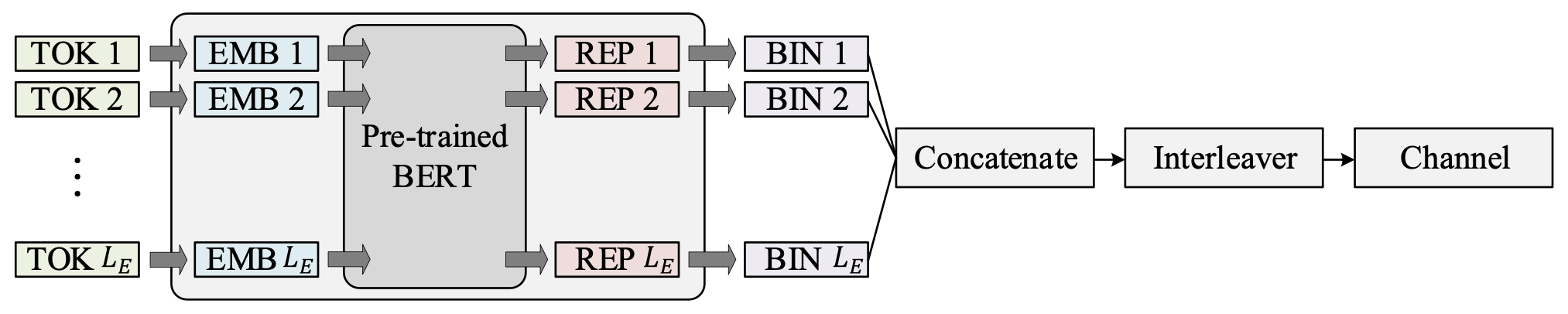
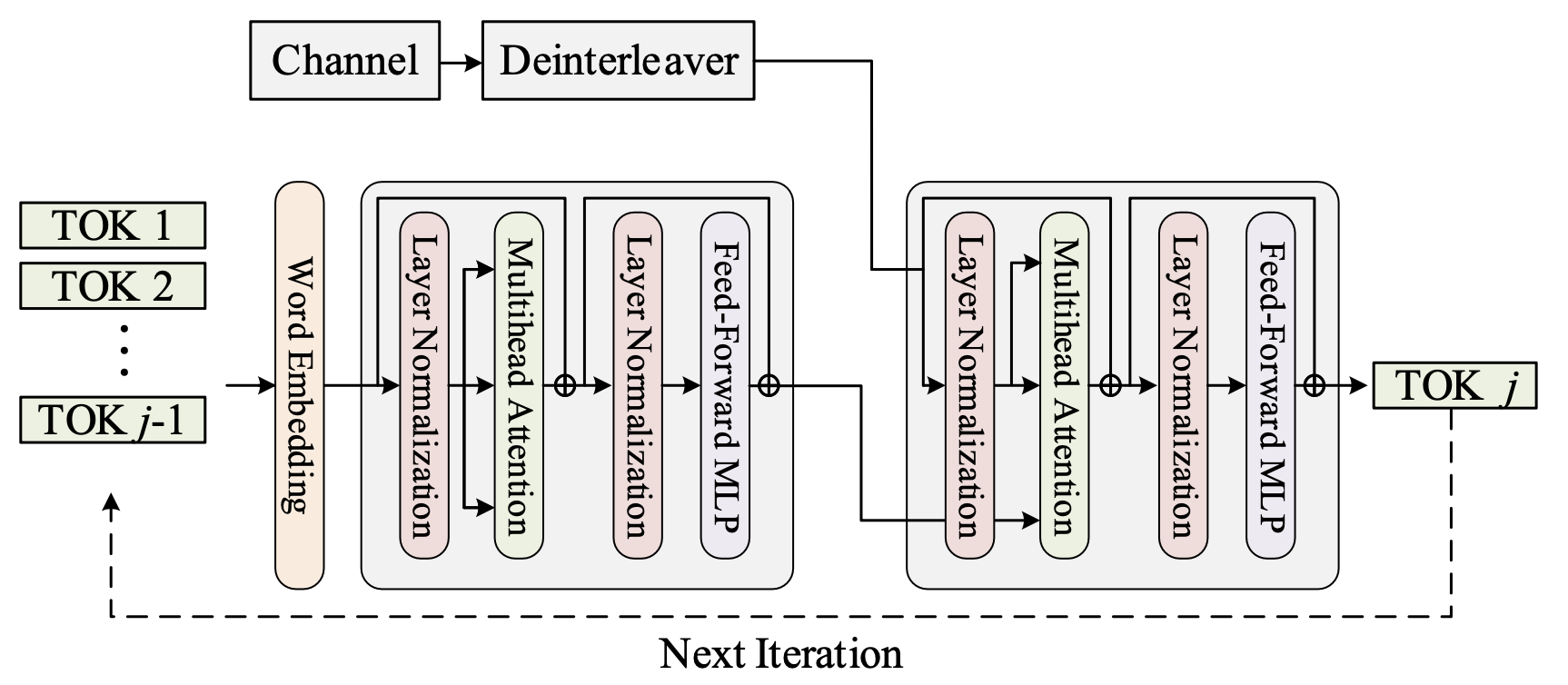
该过程中不存在复杂的数学描述,因此此处不再赘述。值得一提的是信道模型,其中我们考虑了三种二进制信道作为等价信道,而这些信道均可以通过目前存在的神经网络组件组成
二进制擦除信道 (BEC)
BEC信道以概率$P_e$擦除传输的比特,取而代之的是“未知”符号。此处编码结果为${-1,1}$,经过擦除信道后的符号集为${-1,0,1}$。该信道的实现为
二进制对称信道 (BSC)
BSC信道也称为二进制翻转信道,以概率$P_e$反转传输的比特。该信道的实现为
二进制删除信道 (DC)
DC信道以概率$P_e$直接丢失传输比特,由于并不知道丢失位置,这种信道对传输的影响最大。
其他 | Setup
数据集的构造
从一个最简单的例子出发,在问候过程中我们有许多问候语可以选择,例如Hello和Hi。显然这两个词汇在语义通信中可以认为高置信度等价,但如果我们采用最简单的自回归数据集,我们就不能期待在输入模型Hello的同时获得Hi的输出。我们需要构造一个复述数据集,通过放宽对输出结果的约束,让模型更多地去学习“语义”信息。这里我们选择了三个短会话语料数据集如下
Multi30K6: 收集了大约 $30,000$ 组多种语言的图像-文本对,其中的图片描绘了日常生活场景,而文本则是对图像信息的描述,常被用于翻译任务。该数据集大多数图像标题都是短句,这适合我们的目标。Microsoft COCO7: 比上述数据集更大,有大约$330,000$图像,每个图片对应了至少来自5个不同的人的文本描述。WikiAnswers8: 由用户们投票选出的Wiki问答相似问题集合。
鉴于Multi30K数据集在一种语言中没有相似含义的文本对,因此我们使用Google T5模型9通过改写英语图像标题来对其进行扩充。 因此,聚合数据集具有两个主要组成部分,即通过相同输入文本监督输出文本的自回归部分,以及通过改写文本监督输出文本的语义相似部分。
评估准则的建立
本问题中我们主要采用三个准则进行评估
- 困惑度 (Perplexity),是$e$指数版的交叉熵损失,直观地表达了平均候选词数量这个指标,从而评估模型的收敛能力。
- 双语替换评估 (Bilingual evaluation understudy, BLEU),通过比对两句话之间相似词汇来判断相似度,并对许多常见特殊情况做了惩罚
- SimCSE10是基于对比学习的预训练BERT语义相似度评估模型。普通的预训练BERT模型直接对语句embedding的结果并不能有效描述语义相似度,而SimCSE通过对比学习调优实现了更好的效果。
仿真结果 | Main Results
首先是根据语料信息配置对比方案。语料库中信源符号分布如图
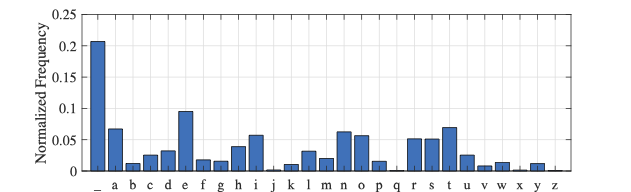
我们容易通过该离散pdf结果推算大致需要的编码比特数为$H=-\sum_{i=1}^{27}p_i\log_2(p_i) = 4.059$比特每符号,而采用霍夫曼信源编码时我们可以获得$\bar{H} = 4.093$ 比特每符号的平均码长。在此结果下,我们采用$1/3$编码速率的Turbo码/LDPC码,则平均每个符号编码为$\bar{H}/R = 12.279$比特,考虑到平均词片为$\bar{L} = 4.588$,那么每个词片的总编码长度是$Q = \lceil \bar{L}\bar{H}/R \rceil = 60$比特。公平对照,我们提出的方案也按照$60$比特长度编码,仿真结果如下

|

|
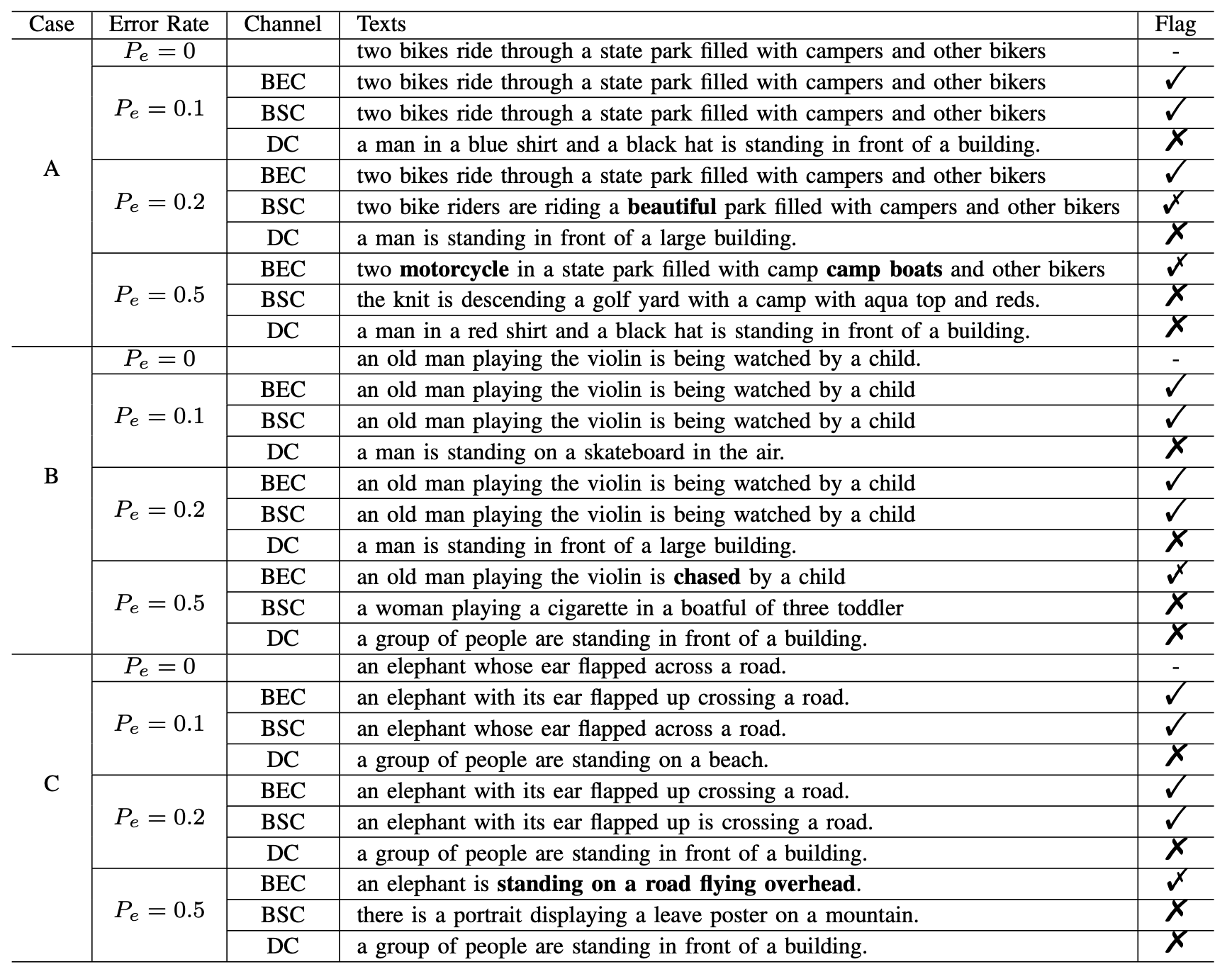
得益于现代通信系统的优秀设计,实际上通信中高达$10\%$误码的场景十分罕见,三倍编码冗余也很难在此条件下实现完美恢复。这种场景实际上很像最前面提到的文本场景,在此条件下,基于语义联合编码的模型则能够实现更好的重建语义相似度,并且能够在$P_e$进一步恶化的条件下延缓性能下降的趋势。BLEU并不是一个完全合格的语义相似度评价指标,但是我们仍然能够看到在BLEU上性能的保持。
不过在两种场景中,我们都很难实现对DC信道的重建,即使误码很低的场景。这是由于DC信道的删除位置未知,对于存在前后依赖的编码块,目前还很难处理相似场景中的问题。此外,由于很显然,$P_e=10\%$已经是很极端的场景,因此我们提出的联合编码方案在进一步压缩编码比特的时候仍有实现高性能重建的潜力,而这将是我们未来工作中的一环。
扩展阅读
-
Y. Liu et al., “Reconfigurable Intelligent Surfaces: Principles and Opportunities,” in IEEE Communications Surveys & Tutorials, vol. 23, no. 3, pp. 1546-1577, thirdquarter 2021, doi: 10.1109/COMST.2021.3077737. ↩
-
F. Liu et al., “Integrated Sensing and Communications: Toward Dual-Functional Wireless Networks for 6G and Beyond,” in IEEE Journal on Selected Areas in Communications, vol. 40, no. 6, pp. 1728-1767, June 2022, doi: 10.1109/JSAC.2022.3156632. ↩
-
Z. Qin, H. Ye, G. Y. Li and B. -H. F. Juang, “Deep Learning in Physical Layer Communications,” in IEEE Wireless Communications, vol. 26, no. 2, pp. 93-99, April 2019, doi: 10.1109/MWC.2019.1800601. ↩
-
W. Weaver, “Recent Contributions to The Mathematical Theory of Communication.” ETC: A Review of General Semantics, vol. 10, no. 4, 1953, pp. 261–81. ↩
-
D. Elliott, S. Frank, K. Sima’an, and L. Specia, ``Multi30K: Multilingual English-German image descriptions,” Proceedings of the 5th Workshop on Vision and Language, pp. 70-74, 2016. ↩
-
T. Lin, et al., ``Microsoft COCO: Common objects in context’’, in Proceedings of European Conference on Computer Vision (ECCV), 2014. ↩
-
A. Fader, L. Zettlemoyer, O. Etzioni, ``Open question answering over curated and extracted knowledge bases’’, Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), New York, NY, USA, pp. 1156-1165, 2014. ↩
-
C. Raffel, et al., ``Exploring the limits of transfer learning with a unified Text-to-Text Transformer’’, Journal of Machine Learning Research, vol. 21, no. 140, pp. 1-67, 2020. ↩
-
SimCSE: Simple Contrastive Learning of Sentence Embeddings ↩